Apache JMeter isn’t the latest or greatest load testing tool out there, but it is still a go to of mine when I’m shaking out a service. It’s free. It’s easy. It’s flexible. I can get some basic useful results from it without a lot of effort. Those qualities make it a particularly nice fit for when you have a bunch of developers, authoring inter-dependent services, your integration tests aren’t all they might be, but you want to make sure things are basically sane before blessing them.
What follows are some of my own best practices that complement or
extend those already widely available from known sources.
Three Layered Test Configurations
Your test suite should be highly configurable, you are testing after all., so you want to avoid constants and hard coded values. Here’s one good way to do that.
- Use a properties file. JMeter will read a Java property file named user.properties from the current working directory. Put all the configuration you can in there: host names, thread count, loop count, etc.
- Use command line overrides. A -Jfoo=bar is an easy way to control per run configuration.
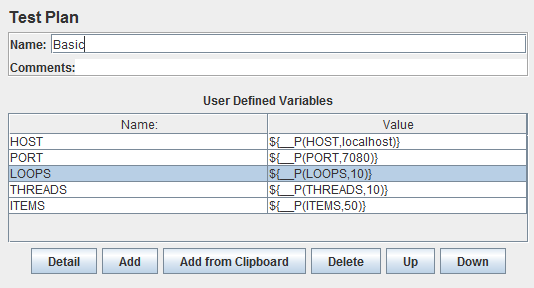
- Move all the properties into variables providing sane defaults. In your test suite variables ate easy to use than properties. So copy the properties into variables using something like ${__P(HOST,localhost)}. That will look up the property HOST, but default the localhost if it isn’t set. I put these in the test plans User Defined Variables section at the start of the plan:
Run it From The Command Line
You’ll likely run this pla over and over, and often back to back with property changes, so get comfortable running it from the command line. I usually script the runs allowing for command line overrides, and post processing (see below). An example command line might resemble:
jmeter.bat -n -t test.jmx -l out.xml -JTHREADS=25 -Jjmeter.save.saveservice.output_format=xml
Synchronization and Sharing
One thing I often hit in test is wanting to share values or code across all my tests. For example, wanting to generate some sequence number that all the threads share to append to data to unique it. The trick here is that JMeter starts up new BeanShell instances in many cases so how do you share code or values across them?
My solution is to create an initial Thread Group with one thread and one loop and in that add BeanShell Samplers there that create values in JMeter’s shared bsh instance. Yup it has one! So for example a shared sequence number could be implemented as follows. First you need to put the value into the shared instance with a BeanShell Sample containing:
import java.util.concurrent.atomic.AtomicInteger; bsh.shared.seqNo = new AtomicInteger(0);
Then you add a BeanShell Sample with some getter code:
generator()
{
String email(String first, String last, Integer sequenceNo) {
return first + "." + last + sequenceNo + "@test.com";
}
return this;
}
bsh.shared.generator = generator();
Now, any BeanShell Sampler that wants a email address with a unique sequence number can:
Integer mySeqNo = bsh.shared.seqNo.getAndIncrement();
String email = bsh.shared.generator.email("Wile", "Coyote", mySeqNo);
Using Results
JMeter has a good collection of Listeners to look at your results with, using the UI is just not optimal if you are running a bunch of passes. You can save the output from many of the listeners but its a manual step. If you are running from the command line as discussed above you can just script a distinct output log name per run and get very granular data out. You’ll get detailed statistics of every run of every sampler. How do you best use all that data? I looked at what was available and didn’t see what I wanted exactly, and many folks agreed, and the consensus seemed to be…. a spreadsheet. Yup. But you know it works pretty well. Depending how good you are with them you can get the data aggregated, sliced, diced and graphed in a jiffy!
For my purposes I took an existing post processing tool, and tuned it up. I generate my logs as XML and then run them through jmeter-out to get nice simple aggregated CSVs that even I can make look good in Excel.
